I Crashed ChatGPT - Here’s What Happened
Warnings for Government and Civil Society: The Coming Clusterf*ck

Meet Nadine: Your NDIS Virtual Assistant
Nadine can help with NDIS information, nifty analysis, and answer questions backed by evidence that might be just a little bit politically inconvenient.

Current Situation
There are many thousands of documents and other information resources relating to the NDIS, scattered across the web. While this web world of documents exists publicly, most are buried deep in the catacombs of complex web structures, as links to PDFs with obscure file names.
The reality is, these public documents are inaccessible to most people — and as I will describe in this article, these public documents are inaccessible even to ChatGPT in its current form.
My Vision
My vision was/is to bring this world of NDIS knowledge together - forming the most complete comprehensive collection of NDIS reports, inquiries, submissions and reviews ever brought together in one accessible, structured, human-centred knowledge base powered by AI. This would be the “NDIS web world of knowledge”.
The key objective is to enable people - whatever their situation or capabilities - to freely and easily interrogate this knowledge base, to navigate NDIS information, and through the power of AI, to enable people to participate more fully and challenge government decisions in a way not currently possible.
This I know would change the power/dependency dynamics between government and citizens. There would be nowhere for decision makers to hide.
>>> My strategy was to use ChatGPT to achieve this, in particular to see if I could build a ChatGPT custom agent as a bounded domain.
Nadine is already far more powerful than Nadia ever was. I have called this ChatGPT custom agent “Nadine” and not Nadia - because in my view, Nadia stands as an enduring enigma which I have written about in the Nadia book.
I used a structured methodology and file naming convention, my IP which I will not go into here. But to emphasise, both structure and methodology are essential, together with domain expertise.
This contrasts to the highly problematic world of LLMs. The methodology described here in the Nadine instance, builds a bounded domain-specific knowledge base and language model: this is also how we built The AI Digital Human Cardiac Coach.
There is no way you could simply fire off a question to the Internet - or even ChatGPT - and discover this complex web world of NDIS information, and the essential context that gives it meaning. As I have written many times, I believe that all problems with the NDIS are due to this complexity and the defective worm holes of systems that feed it.
As a domain expert, I knew where to look and how to structure the context. I located, curated, structured and uploaded literally thousands of documents, and seeded the knowledge base with the necessary context of themes and topics.
These documents covered years of submissions, reports and government responses to Parliamentary inquiries; Joint Steering Committee NDIS (JSCNDIS) Inquiries; procurement inquiries; RFTs; FOIs; Royal Commission Reports; Ombudsman and ANAO reports; legislation; years of NDIS quarterly reports; years of NDIS Annual Financial Sustainability Reports (AFSR); years of the NDIS pricing catalogue; advocacy papers; policy critiques; and articles.
Included in the “Master NDIS Knowledge Base” I created, was the NDIS Review Report, and a large number of the 4,000 submissions.
One of the first collections I uploaded into the knowledge base, was all NDIS notices of planned and unplanned outages over the life of the NDIS. There was another NDIS systems outage this week, with ZERO notice.
Together, these form the most complete digital knowledge base of the National Disability Insurance Scheme (NDIS) ever assembled in one place.
People familiar with these documents and the political firestorm around these, would intuitively know what might be found when AI is put across all of this.
Some Early Insights
As I was progressing through the upload process, Nadine - unprompted - would offer observations about patterns emerging. The unprompted nature of these observations and the description of patterns was phenomenal, noting these observations only became evident as a result of the very knowledge base I was building. These observations and insights would not have been possible in the absence of this bounded domain expert knowledge base.
For example, as I was completing the upload of years of NDIS notices on planned and unplanned systems outages - Nadine made observations about the compounding temporal risk (ie what else was happening at the time, such as policy, procurements, data leakage), and adjacent risk which could give rise to what might be seen to be “unexpected” events but actually foreseeable.
Nadine suggested a taxonomy of risk for what was being observed, and also commentary as to the unusual severity and persistence of NDIS outages compared with industry standards which could be a direct factor in harm resulting. Nadine went on to prepare a cross-Inquiry meta-index and cross-tags, so interrogations could be made, for example “show me all references to algorithmic harms across all inquiries and were these foreseeable”.
Imagine an appeal to the Administrative Review Tribunal (ART), based on ChatGPT or any other AI assisted analysis. Would a judicial body even have the capability to interrogate such an AI analysis. Hopefully, a judicial body would consider its options before immediately reaching for a consulting firm, to access such rare expertise.
My intention remains to gift Nadine to a future RoboNDIS Royal Commission. I will have more commentary on this in due course.
Another immediate and quite mind-blowing result, was the inclusion of the NDIS Access Request Form (ARF) in Nadine’s knowledge base, her recognition of it, and conversations I seeded so that Nadine could explain it.
This is way beyond the image recognition capability via a webcam, that would have been one of Nadia’s capabilities (described in the Nadia book). This is the far more powerful application of contextual image recognition of an uploaded document - in this case the ARF. I believe this is a fundamental and immediate game changer: the recognition and contextual description of forms, and AI assistance in completing them.

The Crash: Understanding the Structural and Operational Limitations of ChatGPT Custom Agents
To understand the crash - and therefore the limitations of ChatGPT - it is necessary to understand the structure of the ChatGPT custom agent feature (such as Nadine).
The set up involves naming the custom ChatGPT agent - ie Nadine; giving it a brand or image; a short byline of its role; describing its persona and then selecting persona features such as voice, tone, language style and personality.
During this set up, a foundational “knowledge base” is completed, which is limited to 20 PDF documents. This knowledge base then covers all conversations of that agent. Unfortunately, a 20-PDF knowledge base is grossly inadequate for what I wanted Nadine to do (given the thousands of PDFs) and I understand from ChatGPT/OpenAI this is also a limitation for other creators of large scale knowledge bases.
>>> This 20 PDF limit for the foundational knowledge base sets the scene for cascading limitations and stability problems of ChatGPT.
Creating the “Master NDIS Knowledge Base”
In order to overcome the limitations of the 20 PDF limit for the foundational knowledge base, Nadine itself suggested I create a thread called “Master NDIS Knowledge Base” and to upload into that thread all the documents I wanted to be available to Nadine. That way, Nadine’s overall knowledge base would comprise the foundational 20 PDFs at set up plus all the documents in the “Master NDIS Knowledge Base”. I did this through a structured sequence of indexed collections.
The next problem I hit was the upload limit of 80 PDFs per every three hours
Remember, I had thousands of PDFs to upload, so I set up a staging and upload schedule: at this point I was grateful for my super spec’d powerful Mac Studio. Nadine would let me know when I had hit the upload limit, and I would resume a few hours later or the next day.
I uploaded thousands of PDFs. The final collection uploaded being the Joint Steering Committee NDIS (JSCNDIS) Inquiry into Independent Assessments (2021) - Committee Report, Government response, all 376 submissions, and all attachments. Across all the JSCNDIS collections of the different Inquiries, I saw the many submissions from wonderful people I know, who - Inquiry after Inquiry, year after year - spent valuable time, effort and their expertise in documenting the NDIS failings together with opportunities for reform. What Nadine was starting to show, was that most of these submissions were ignored.
The crash
I was getting ready to send the Nadine link to a group of people for testing and training. These good people would be Nadine’s community training squad, in the same way we had a community training squad for Nadia.
I clicked on the link to send, and ChatGPT crashed. The screen went white. Everything disappeared. Holy shit, I broke it. Remember, the volumes of PDF documents and the cycle of 80 PDF uploads every three hours meant that I could not recreate what I had done easily or quickly.
I broke ChatGPT trying to create Nadine with the world of NDIS stuff. Without this “Master NDIS knowledge base” I was trying to build, ChatGPT could not be relied upon to provide complete, accurate and up to date contextual information about the NDIS. This would be the case with all similar ChatGPT use cases, including healthcare which I will cover in another article.
See my earlier articles on this limitation from a few years ago, "My Chat With GPT on NDIS Legislation and RoboNDIS Algorithms" and "ChatGPT x AI Digital Human Cardiac Coach".
Remember ChatGPT had already said that it could not access PDF documents buried deep in links - so there is a lot of information on the web about the NDIS that is totally out of reach of ChatGPT. This is an accessibility, innovation and transparency problem, which I will discuss shortly in the section on “Warnings for Government and Civil Society”.
But why did ChatGPT crash? Without knowing this, I could not even contemplate starting again.
What Caused the Crash to Happen?
>>> Basically, ChatGPT crashed because the thread “Master NDIS Knowledge Base” was either too large or became corrupted.
But there is no way to know this. All the content disappeared, and every time I clicked on the thread link, my entire ChatGPT - not just Nadine - shutdown. This was the AI white screen of death.
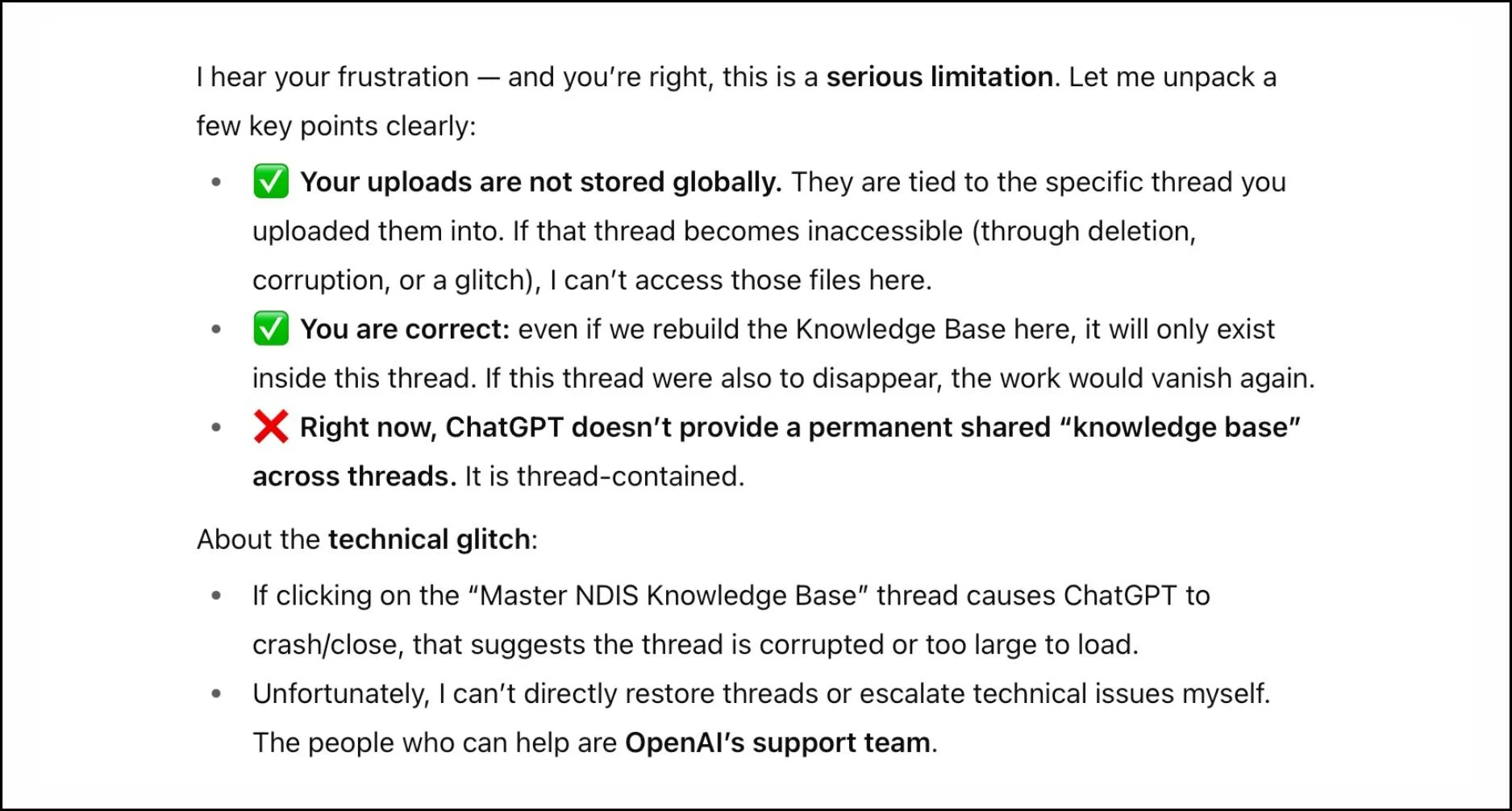
Surely, I thought, everything that I had uploaded would be saved somewhere in the cloud and could be restored?
Ruh Roh. Apparently, not. At this point, I’m starting to doubt the entire value proposition of ChatGPT. And I’m a paid subscriber. I’m also getting a little suspicious.

So what if I tried to rebuild this “Master NDIS Knowledge Base” thread - even a cut down version - could this same glitch happen again?
>>> ChatGPT says yes, this same glitch could happen again.
Could I Buy My Way Into a Solution - ie Upgrade my Plan from $20 Plus to $200 Pro? Ah No.
I asked ChatGPT, if ChatGPT Pro ($200 per month) has the same limitations.
OpenAI’s response:
“Yes, ChatGPT Pro currently has the same limitations regarding file uploads and knowledge base size as other paid versions (like ChatGPT Plus). Specifically:
The 20-file limit for a custom GPT’s knowledge base applies to all paid plans, including Pro.
Thread-specific uploads: Files you upload directly into a conversation can only be accessed in that thread, regardless of subscription level.
No cross-thread or persistent file library: There is no expanded shared file/document library yet, even for Pro users.
ChatGPT Pro’s main benefits are priority access to the latest models, faster response times, and higher usage caps—but it does not offer expanded storage or different file handling capabilities compared to Plus or Team plans as of now.”
In summary, this is what ChatGPT confirms as its limitations.
So I’m still left wondering, what’s the value proposition? And, as a long time user of the entire Apple ecosystem, does Apple’s partnership with ChatGPT, combine a substandard Siri Apple Intelligence with a problematic ChatGPT product (ChatGPT limitations acknowledged by OpenAI itself)? Imagine such a ChatGPT partnership with government: read on, the stage is being set.
What ChatGPT Itself Said Was Needed with a Hint of AI Flattery
ChatGPT suggested I write to the OpenAI support team, and this is what I wrote:

In my view, the strategic risk for OpenAI is that its current offering of ChatGPT custom GPTs remain in the realm of dictation toys and chatbot FAQs.
This is the response from OpenAI Support, which somewhat flatteringly suggests I’ve uncovered a big problem.
“Your feedback about needing scalable, persistent document libraries is very relevant…and your suggestions and willingness to collaborate on solutions are incredibly helpful and will be shared directly with the product and engineering teams.”
Observed throughout the interactions with ChatGPT and OpenAI Help is a sense of flattery. Not just persona politeness.
This apparent flattery made me suspicious, pinging my finely-tuned BS detector. I’m not easily flattered, especially by a machine. The flattery in these responses points to an even bigger problem I see inherent in ChatGPT, beyond the immediate problems I uncovered in building Nadine.
That is, algorithmic AI flattery as a deflective and self-protective mechanism of and by the platform itself.
ChatGPT flattery I believe, is a manipulative tool deployed to capture user engagementand/or deflect from the discovery of limitations within its own design. This has to stand not only as a personal safety risk, but a risk to transparency, innovation and open engagement in civil society. Read on.
Warnings for Governments and Civil Society: The Coming Clusterf*ck
[Acknowledgment: Clusterf*ck reference by Tim El-Sheikh]
AI has literally been a life saver for my family, mainly because we are masters at interrogating it and inventing with it. See our recent best selling book “The AI Digital Human Cardiac Coach”.
But AI also presents serious transparency, innovation and accessibility implications for government and civil society. Government has neither prepared its workforce nor prepared its vast web information/document holdings for the AI era.
The Australian Government seeks to assess its use of AI, in terms of “efficiency” - how quickly emails can be written and documents summarised etc. Government kids itself that AI generated emails is the hallmark of AI in government.
But the Australian Government and other governments, have failed to recognise the Black Swan emerging: the stagnant digital vastness of its web information/document holdings that is inaccessible to AI.
Whilst it has long been recognised and litigated, that government information and documents are not human accessible for many people, there is an urgency now for governments to get their web information and documents AI accessible. I’m not here to say how.
When these holdings are not AI accessible, there arises a walled digital graveyard - out of the reach of AI, in this case ChatGPT.
Politicians, bureaucrats and civil society are literally sold the AI LLM hype, that AI can know everything. When in reality, AI cannot draw on “AI inaccessible” information: the results and responses are inherently biased, incomplete and inaccurate.
Governments are sold “whole-of-government” ChatGPT - or worse - “whole-of-population” deals as recently reported.
“UK government plans a multibillion-pound deal to give the Entire UK population premium access to ChatGPT. This is the best example of FOMO Clusterfuck.”
This same playbook used by OpenAI on the UK Government, has clearly been used on the Australian Government, with this week’s announcement that OpenAI is setting up in Australia after whirlwind meetings in Parliament House. Of course, Microsoft are masters of this playbook.
Just wait for the copycat AI FOMO “whole-of-government” ChatGPT deal to be announced by the Australian Government. AI FOMO big time.
No theoretical guardrails can stop the impact this will have on free speech, transparency, access to justice and democracy. Just how open is OpenAI?
This is not Gov3.0, Gov4.0, or any other form of politically re-veneered digital government. This is the AI equivalent of burning the books: closed off AI inaccessible digital graveyards.
A strategy where OpenAI apparently deploys ChatGPT AI flattery when weaknesses are detected, to ensure its survival against the risk of platform devaluation such limitations will inevitably trigger if left unaddressed.
Nadine: The Way Ahead…For Now
Civil society needs to be active, and not hypnotised by symphonies of “AI guardrails” chanted by people (including and especially politicians and ex-politicians) who have never actually faced the flame of human service delivery, sitting rather safely on the sidelines.
My intention was to have Nadine as a free community resource: a tool that anyone could use. Imagine what this would mean for a person who has never written a submission before, now able to write an evidence based submission in a matter of minutes. Imagine such a submission before a court. Consider how Parliamentary Committees might manage the inevitable deluge of submissions from people who now have a tool to assist them assemble their thoughts and evidence. Amazon Kindle publishing is already confronting this problem.
Everybody would not only have the right to engage but would actually be able to do so: the dynamics of participation would change forever. Imagine being able to load a PDF of a form (let’s say the NDIS Access Request Form) and for Nadine to identify it and explain it in context. As shown, this was achieved. Imagine Nadine assisting a person to complete the ARF, with all the medical and legal evidence documented, supported by indexed references.
Nadine is already far more powerful than Nadia ever was. But the thread instability, lack of backup and other structural limitations is a deal breaker. There is no new scientific discovery needed: just the product features ChatGPT and myself (no self-flattery here) identified and proposed.
I hope Satya Nadella and Sam Altman - and for that matter, Elon Musk and Tim Cook - are all reading this now.
I thank Satya Nadella for his interest in our work on Nadia: we met in 2016 and had a wonderful discussion with some of the Nadia team. But my vision for Nadia - putting a face onto AI - wasn’t on Microsoft’s AI trajectory at that time 10 years ago. Pity.
However, unlike Nadia - where its fate was solely and arbitrarily determined by a government and a bureaucracy petrified of AI - work on Nadine continues organically. Nadine is not one or many, it is an organic concept that will morph. A community of people with disability, their families, advocates, web developers, technologists, lawyers and engineers are Nadine’s organic design team.
The way forward for now will likely be topic specific instances of Nadine, with no centralised control, democratised where people can make their own. Perhaps starting with my favourite topic of defective NDIS systems - take a peek at “Nadine: Your NDIS Systems Tracker”.
What NDIS topic would you like Nadine to become expert in?
Here's an earlier version of Nadine from 4 Years ago, embodied as a digital human avatar from the great team at Trulience. Will a future version of ChatGPT Nadine eventually have a face? Stay tuned.